MySQL Illegal mix of collations エラーが出る・出ないまとめ
Illegal mix of collations
Illegal mix of collations エラーは 異なる照合順序で結合や比較を行った場合に発生するエラーです。
mysql> SELECT CONCAT(_utf8mb4 'A' COLLATE utf8mb4_bin, _utf8mb4 'B' COLLATE utf8mb4_unicode_ci); ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_bin,EXPLICIT) and (utf8mb4_unicode_ci,EXPLICIT) for operation 'concat' mysql> SELECT _utf8mb4 'A' COLLATE utf8mb4_bin = _utf8mb4 'B' COLLATE utf8mb4_unicode_ci; ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_bin,EXPLICIT) and (utf8mb4_unicode_ci,EXPLICIT) for operation '='
エラーが発生しない場合もある
照合順序が異なっていても、エラーにならないケースもあります。
latin1_swedish_ci と utf8mb4_unicode_ci と異なる照合順序で比較していますが、エラーなく実行することが出来てます。
mysql> SELECT _latin1 'A' COLLATE latin1_swedish_ci = _utf8mb4 'B' COLLATE utf8mb4_unicode_ci AS r; +------+ | r | +------+ | 0 | +------+ 1 row in set (0.00 sec)
Illegal mix of collations エラーが発生する・しない まとめ
雑なコードを書いて、主な照合順序を総当たりでチェックしてみました*1。
| name | sjis_japanese_ci | sjis_bin | ujis_japanese_ci | ujis_bin | utf8_general_ci | utf8_unicode_ci | utf8_bin | utf8mb4_general_ci | utf8mb4_unicode_ci | utf8mb4_bin | latin1_swedish_ci | latin1_bin | ascii_general_ci | ascii_bin |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sjis_japanese_ci | - | ERR | ERR | ERR | OK | OK | OK | OK | OK | OK | ERR | ERR | ERR | ERR |
| sjis_bin | ERR | - | ERR | ERR | OK | OK | OK | OK | OK | OK | ERR | ERR | ERR | ERR |
| ujis_japanese_ci | ERR | ERR | - | ERR | OK | OK | OK | OK | OK | OK | ERR | ERR | ERR | ERR |
| ujis_bin | ERR | ERR | ERR | - | OK | OK | OK | OK | OK | OK | ERR | ERR | ERR | ERR |
| utf8_general_ci | OK | OK | OK | OK | - | ERR | ERR | OK | OK | OK | OK | OK | OK | OK |
| utf8_unicode_ci | OK | OK | OK | OK | ERR | - | ERR | OK | OK | OK | OK | OK | OK | OK |
| utf8_bin | OK | OK | OK | OK | ERR | ERR | - | OK | OK | OK | OK | OK | OK | OK |
| utf8mb4_general_ci | OK | OK | OK | OK | OK | OK | OK | - | ERR | ERR | OK | OK | OK | OK |
| utf8mb4_unicode_ci | OK | OK | OK | OK | OK | OK | OK | ERR | - | ERR | OK | OK | OK | OK |
| utf8mb4_bin | OK | OK | OK | OK | OK | OK | OK | ERR | ERR | - | OK | OK | OK | OK |
| latin1_swedish_ci | ERR | ERR | ERR | ERR | OK | OK | OK | OK | OK | OK | - | ERR | ERR | ERR |
| latin1_bin | ERR | ERR | ERR | ERR | OK | OK | OK | OK | OK | OK | ERR | - | ERR | ERR |
| ascii_general_ci | ERR | ERR | ERR | ERR | OK | OK | OK | OK | OK | OK | ERR | ERR | - | ERR |
| ascii_bin | ERR | ERR | ERR | ERR | OK | OK | OK | OK | OK | OK | ERR | ERR | ERR | - |
utf8, utf8mb4 は他のキャラクタセットとの比較が可能
mysql> SELECT _utf8mb4"A" COLLATE utf8mb4_general_ci = _sjis"A" COLLATE sjis_japanese_ci; +----------------------------------------------------------------------------+ | _utf8mb4"A" COLLATE utf8mb4_general_ci = _sjis"A" COLLATE sjis_japanese_ci | +----------------------------------------------------------------------------+ | 1 | +----------------------------------------------------------------------------+ 1 row in set (0.00 sec)
ただし、同じ UTF8 の他の照合順序 (例:utf8mb4_general_ci vs utf8mb4_unicode_ci) とは比較できない
mysql> SELECT _utf8mb4"A" COLLATE utf8mb4_general_ci = _utf8mb4"A" COLLATE utf8mb4_unicode_ci; ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_general_ci,EXPLICIT) and (utf8mb4_unicode_ci,EXPLICIT) for operation '='
一方、uft8, utf8mb4 以外はキャラクタセット・照合順序が一致していないと比較できない。
mysql> SELECT _sjis"A" COLLATE sjis_bin = _sjis"A" COLLATE sjis_japanese_ci; ERROR 1267 (HY000): Illegal mix of collations (sjis_bin,EXPLICIT) and (sjis_japanese_ci,EXPLICIT) for operation '='
という、法則のようです。
*1:version 5.7.37 で試しました
MySQL Shell のパラレルテーブルインポートの実装がスマートだった件
MySQL Shell のパラレルテーブルインポートの実装が興味深かった
MySQL Shell のパラレルテーブルインポート
MySQL Shell 8.0.17 で導入された MySQL Shell パラレルテーブルインポートユーティリティ util.importTable() は、大規模なデータファイルの MySQL リレーショナルテーブルへの高速データインポートを提供します。 このユーティリティは、入力データファイルを分析してチャンクに配布し、パラレル接続を使用してチャンクをターゲット MySQL サーバーにアップロードします。 このユーティリティは、LOAD DATA ステートメントを使用した標準のシングルスレッドアップロードよりも数回高速に大規模データインポートを完了できます。 https://dev.mysql.com/doc/mysql-shell/8.0/ja/mysql-shell-utilities-parallel-table.html
MySQL Shell にはインポート機能があります。
このインポート機能は1つのファイルを小分けにして(チャンクにして)、並列でテーブルにインポートすることで、高速に動作します。内部の実装には上記の説明にあるとおり、LOAD DATA ステートメントが利用されています。
mysqlsh> util.import_table("products.csv", {"dialect": "csv-unix", "table": "products"})'
どのように実装されているか
パラレル機能はどのように実装されているのでしょうか。ごく単純な実装として、インポート対象のファイルを分割したファイルをまず用意し、それを LOAD DATA で並列にインポートする流れが思いつきます。
しかし、実際は、このような実装になっていません(もうちょっと賢い実装になってる)。
インポート中に流れているSQL
インポート中に実行されているSQLを見ると、同じ LOAD DATA が並列に実行されていました。
LOAD DATA で指定されているファイルは全て同じファイル (import_table で指定したファイル名 /src/data/products.csv ) になっています。
mysql> SHOW FULL PROCESSLIST \G
<snip>
*************************** 4. row ***************************
Id: 232
User: root
Host: localhost
db: onlinemall
Command: Query
Time: 5
State: executing
Info: LOAD DATA LOCAL INFILE '/src/data/products.csv' INTO TABLE `onlinemall`.`products` FIELDS TERMINATED BY ',' ENCLOSED BY '\"' ESCAPED BY '\\' LINES STARTING BY '' TERMINATED BY '\n'
*************************** 5. row ***************************
Id: 233
User: root
Host: localhost
db: onlinemall
Command: Query
Time: 5
State: executing
Info: LOAD DATA LOCAL INFILE '/src/data/products.csv' INTO TABLE `onlinemall`.`products` FIELDS TERMINATED BY ',' ENCLOSED BY '\"' ESCAPED BY '\\' LINES STARTING BY '' TERMINATED BY '\n'
*************************** 6. row ***************************
Id: 234
User: root
Host: localhost
db: onlinemall
Command: Query
Time: 5
State: executing
Info: LOAD DATA LOCAL INFILE '/src/data/products.csv' INTO TABLE `onlinemall`.`products` FIELDS TERMINATED BY ',' ENCLOSED BY '\"' ESCAPED BY '\\' LINES STARTING BY '' TERMINATED BY '\n'
通常であれば、これはまったく意味のない行為です。重複エラーになるでしょうし、パフォーマンス面でもメリットはありません。
しかし、MySQL Shell は LOAD DATA のプロトコルの仕様をうまく活用して、実際は高速なデータロードを実現しています。
LOAD DATA のフロー
LOAD DATAのフローは特殊です。サーバは LOAD DATA を受け取ると、クライアントにファイルの内容を送るようリクエストします。 INSERT や UPDATE と違って、クエリにデータが含まれていませんから、クライアントにファイルの中身を別途、送ってもらう必要があるわけです。
このあたりは、@tmtms さんの解説が詳しいです。
@tmtms さんのブログから図をお借りしました
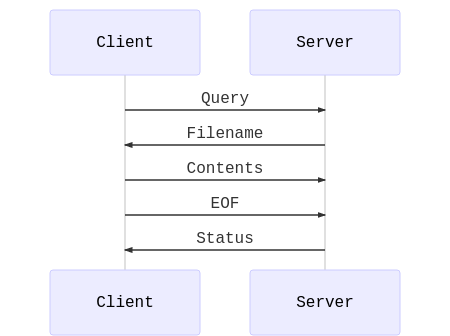
パラレルテーブルインポートの実装
MySQL Shell は上記の仕様をうまく使って、該当のコネクションが担当する範囲(チャンク)のみをサーバに返しています。 つまり、各コネクションは同じファイルをサーバ側から読むようにリクエストされたにも関わらず、実際には異なる内容をレスポンスしています。
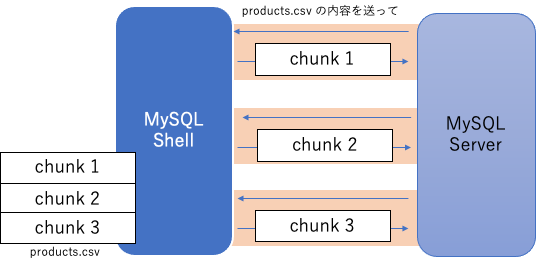
圧縮ファイルの扱いも同じ
このインポートユーティリティは圧縮されたファイルも扱えます。
mysqlsh> util.import_table("products.csv.gz", {"dialect": "csv-unix", "table": "products"})'
同様の流れで、解凍した内容をサーバに返すことで、本来は LOAD DATA がサポートしていない、圧縮ファイルを LOAD DATA できるように見せかけてます。 賢いですね〜。
-- 普通はエラーになる mysql> LOAD DATA LOCAL INFILE '/src/data/products.csv.gz' INTO TABLE `onlinemall`.`products` FIELDS TERMINATED BY ',' ENCLOSED BY '\"' ESCAPED BY '\\' LINES STARTING BY '' TERMINATED BY '\n'; ERROR 1300 (HY000): Invalid utf8mb4 character string: ''
-- MySQL Shell からだと実行できているように見える
<snip>
*************************** 4. row ***************************
Id: 225
User: root
Host: localhost
db: onlinemall
Command: Query
Time: 117
State: executing
Info: LOAD DATA LOCAL INFILE '/src/data/products.csv.gz' INTO TABLE `onlinemall`.`products` FIELDS TERMINATED BY ',' ENCLOSED BY '\"' ESCAPED BY '\\' LINES STARTING BY '' TERMINATED BY '\n'
4 rows in set (0.00 sec)
まとめ
LOAD DATAのファイル名は飾り
MySQL mysql コマンドからシェルを呼び出せなくする小技
mysql コマンドでは ! や system によって、シェルを呼び出すことができます。
mysql> \! uname Linux mysql> system uname Linux
実装はシンプルで、標準ライブラリの system 関数が利用されています。
static int
com_shell(String *buffer MY_ATTRIBUTE((unused)),
char *line MY_ATTRIBUTE((unused)))
{
char *shell_cmd;
/* Skip space from line begin */
while (my_isspace(charset_info, *line))
line++;
if (!(shell_cmd = strchr(line, ' ')))
{
put_info("Usage: \\! shell-command", INFO_ERROR);
return -1;
}
/*
The output of the shell command does not
get directed to the pager or the outfile
*/
if (system(shell_cmd) == -1)
{
put_info(strerror(errno), INFO_ERROR, errno);
return -1;
}
return 0;
}
system を使えなくする
LD_PRELOAD を使って、標準ライブラリの system 関数を差し替えてしまいましょう。
ダミーの system 関数を作ります。
#include <stdlib.h>
#include <stdio.h>
int system(const char *command) {
fprintf(stderr, "system command is prohibited\n");
return 0;
}
$ gcc -g -Wall -fPIC -shared -o nosystem.so nosystem.c
$ LD_PRELOAD=$PWD/nosystem.so mysql mysql> \! uname system command is prohibited mysql> system uname system command is prohibited
使えなくなりました。めでたしめでたし(LD_PRELOAD を強制する方法は、省略。。。)
MySQL 8.0 で謎のEXPLAIN結果が出なくなってた
時々、頭の中でMySQLの気持ちになって考えた実行計画と違うものが出力されるときがあるんですよね。 まぁ、実用上、問題になることはなかったので、「MySQL ヨクワカランなー」と思って、スルーしてました。
ところが、最近、MySQL 8.0 をいじってたら、イメージしている実行計画が表示されてることに気づきました。ワイワイ!
MySQL 5.7 の謎の Index Condition Pushdown 表示
今回のお題のテーブルはこちら(Employees Sample DBに 適当にカラム c1 を追加したもの)
mysql> SHOW CREATE TABLE salaries \G
*************************** 1. row ***************************
Table: salaries
Create Table: CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
`c1` int(11) DEFAULT NULL,
PRIMARY KEY (`emp_no`,`from_date`),
KEY `idx1` (`to_date`,`c1`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
to_date と c1 にインデックスを貼ってあります。
説明のため、ベースとなる実行計画を示します。
idx1 インデックスから to_date と c1 の条件にマッチするレコードを引き当ててます。Extra は NULL です。
これは違和感のない実行計画です。
mysql> EXPLAIN SELECT * FROM salaries
WHERE to_date = '2010-10-10' AND c1 = 0 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: ref
possible_keys: idx1
key: idx1
key_len: 8
ref: const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
このクエリに ORDER BY salary をつけると、Extra に Using index condition が出現します。
mysql> EXPLAIN SELECT * FROM salaries
WHERE to_date = '2010-10-10' AND c1 = 0 ORDER BY salary\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: ref
possible_keys: idx1
key: idx1
key_len: 8
ref: const,const
rows: 1
filtered: 100.00
Extra: Using index condition; Using filesort
1 row in set, 1 warning (0.00 sec)
to_date = '2010-10-10' AND c1 = 0 は、等価比較なので、インデックスコンディションプッシュダウン で解決する必要はありません。
その証拠にベースのクエリでは、Using index condtion は出てない。
ベースのクエリにソートが加わるのみなので、Extra に Using filesort だけが追加されるんじゃないの・・・?
MySQL 8.0 の実行計画
同じ条件で、MySQL 8.0 の実行計画を見てみます。
mysql> EXPLAIN SELECT * FROM salaries
-> WHERE to_date = '2010-10-10' AND c1 = 0 ORDER BY salary\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: ref
possible_keys: idx1
key: idx1
key_len: 8
ref: const,const
rows: 1
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
謎の Using index condtion がなくなったぞー👏👏👏
ちなみに、実行速度の変化は、未確認です。そもそも、EXPLAIN表示上のだけの問題だった可能性もありそう。
MySQL The client was disconnected by the server because of inactivity の対処方法
3ヶ月ブログをサボっておりました。。。リハビリがてらのエントリー。
The client was disconnected by the server because of inactivity エラー
MySQL 8.0.24 からタイムアウト(wait_timeout / interactive_timeout)時のエラーメッセージがに変更になりました。
8.0.24 以前 (Before)
MySQL server has gone away もしくは Lost connection to MySQL server during query
8.0.24 以降 (After)
The client was disconnected by the server because of inactivity. See wait_timeout and interactive_timeout for configuring this behavior.
以前のエラーメッセージは単に接続が切れたことのみを示しています。
タイムアウトした場合も、ネットワークが切れた場合も、max_allowed_packet が小さすぎる場合も・・・「MySQL server has gone away」エラーでした。
原因は別途切り分ける必要がありました。
8.0.24 以降では、wait_timeout / interactive_timeout が原因でタイムアウトした場合は、その旨をエラーメッセージで明確に表示してくれるようになりました。 わかりやすい!
対処方法
The client was disconnected by the server because of inactivity エラー はアイドル時間が wait_timeout / interactive_timeout 値を超えたことで発生します。
「wait_timeout (CLIの場合、interactive_timeout)の設定を長くする」もしくは「アイドル時間が長くならないよう処理の流れを見直す」ことで解決します。
mysql> SET GLOBAL wait_timeout=XXX
参考
先月、MySQL8.0.24リリースノートでわいわい言う勉強会 に参加して、8.0.24 の変更点についてLTしてきました。
参考書籍

MySQL Orchestrator RecoveryPeriodBlockSeconds と FailureDetectionPeriodBlockMinutes の違い
Orchestrator
orchestrator は マスターの障害検知およびレプリカのマスター昇格(フェイルオーバー)を自動で行うソフトウェアです。 MySQLのマスター昇格といえば、MHAがデファクトスタンダードでしたが、MHAはメンテナンスモードになって久しい・・・ということで、最近は orchestrator が使われることが多い印象です。メルカリさんで使われたりしているようです。
アンチ フラッピング機構 RecoveryPeriodBlockSeconds
orchestrator にはアンチフラピング機構が備わってます。orchestratorにおける、フラッピングとは、フェイルオーバーが繰り返し短時間に発生する状況を指します。
障害が短期間に連続して発生する状況は、何か予期せぬ事態が起きている可能性が高いです。このような状況では、ヘタに自動的にフェイルオーバーするよりは、人間がしっかりと状況を確認し、対応するほうが好ましいでしょう。
orchestrator では一度、リカバリ(レプリカのマスター昇格)を実行したら、RecoveryPeriodBlockSeconds で指定した期間(秒)経過するまで、リカバリが発動しないように制御されています。
orchestrator avoid flapping (cascading failures causing continuous outage and elimination of resources) by introducing a block period, where on any given cluster, orchesrartor will not kick in automated recovery on an interval smaller than said period, unless cleared to do so by a human. https://github.com/openark/orchestrator/blob/master/docs/topology-recovery.md
FailureDetectionPeriodBlockMinutes
もう1つ似たようなパラメータとして、FailureDetectionPeriodBlockMinutes があります。
障害を検知したら、FailureDetectionPeriodBlockMinutes で指定した期間(分)、障害の検知を行いません*1。
障害検知が行われなければ、リカバリも行われないので、「RecoveryPeriodBlockSeconds と同じやん・・・*2」と思いましたが、以下の記述で納得できました。
Detection does not always lead to recovery. There are scenarios where a recovery is undesired: https://github.com/openark/orchestrator/blob/master/docs/failure-detection.md
orchestrator では、障害の検知(FailureDetection)= リカバリ(マスター昇格)発動 とは限りません。
orchestrator は 障害検知からマスター昇格完了までの各ポイントで、任意のスクリプトを実行するためのHookが設けられています。
PreFailoverProcesses で指定したスクリプトで、エラーを返すことで、リカバリの発動を止めることができます。
フェイルオーバーに関する Hook)
* OnFailureDetectionProcesses * 障害検知時 * PreFailoverProcesses * フェイルオーバー発動前 * PostMasterFailoverProcesses * マスターのフェイルオーバー後 * PostFailoverProcesses * レプリカも含めて、全てのフェイルオーバーが完了したタイミング
--
FailureDetectionPeriodBlockMinutes の説明には、anti-spam mechanism と書いてあります。
これは、OnFailureDetectionProcesses フックで、障害通知を行っているようなケースを想定して、「アンチスパム」と表現しているのでしょう。
FailureDetectionPeriodBlockMinutes is an anti-spam mechanism that blocks orchestrator from notifying the same detection again and again and again.
まとめ
RecoveryPeriodBlockSecondsは短期間にフェイルオーバーが連続発生しないようにするためのパラメータ- 障害の検知(FailureDetection)= リカバリ(マスター昇格)発動 とは限らない
FailureDetectionPeriodBlockMinutesは 障害継続時 にOnFailureDetectionProcessesで指定したスクリプトを実行する間隔
僕が本当に知りたかったこと
ごく短時間のダウンではフェイルオーバーを発動させたくないんだが、Hookで作り込むしかないんだろうか(誰か教えてください)
*1:チェックする間隔はまた別のパラメータなので注意
*2:スマートスタイルの記事でも、FailureDetectionPeriodBlockMinutes がフラッピング対策と説明されているので、同じように考えてしまう人は多そう http://blog.s-style.co.jp/2018/11/2875/
MySQL 論理削除に関する個人的見解まとめ
技術顧問や講演の場で、論理削除について見解を聞かれる場面がよくあります。アプリケーション開発者の方にとって、身近なデータベースの疑問なんでしょうね。
しっかり言語化できてなかったので、ブログに書いておきます。
論理削除をどう考えるかは、諸派あるんだろうと思ってます。 自分の意見が正しいと言うつもりはありませんし、求めらる要件や環境で結論が変わることもあると思います。
論理削除とは(おさらい)
以下のように削除日付(deleted_at)のカラムを設けて、レコードの有効・無効を管理する手法を指します。
| id | name | deleted_at |
|---|---|---|
| 1 | aaaaaa | NULL |
| 2 | bbbbbb | 2021-01-12 10:00:00 |
論理「削除」と呼びますが、実際は、非表示フラグやレコードの状態遷移を表していたり。よくよく考えると「削除」でないパターンも含まれています。逆に、DELETE して完全にデータを削除することを「物理削除」と呼びます。
誤操作の取り消しが、論理削除を採用する代表的な目的でしょう。
誤操作の保険としてはバックアップもありますが、バックアップは、データベース全体の時間軸を戻すことを意図したものです。 特定のレコードに絞って時間軸を戻すのには適していません。
論理削除のデメリットと言われているもの
バグの温床になりやすい
WHERE 句に deleted_at IS NULL を付けまくらないといけないというやつですね。deleted_at IS NULL を付け忘れると削除済みデータが見えてしまうと。
パフォーマンスへの影響
本来必要のないレコードが保存されることで、そのぶんオーバーヘッドになる。
ぼくの見解
論理削除をそれほど、強いアンチパターンだとは考えてません。他のアンチパターンと比較すると問題になる確率も低いように思います。 自分の周囲では論理削除が問題になっているケースをほとんど見たことがないです。
もちろん物理削除のほうがデータがクリーンで好ましいと思います。ただ、論理削除を撲滅するために、大きな労力を割く必要は感じないです。
パフォーマンス影響については、論理削除の有無より他の要素に左右されるケースがほとんどだと思います。
むしろ、現場では、貯め続けていると、そのうち明らかに問題になるデータ量なのに、ノーガードで運用されているケース に出くわすほうが多いです。論理削除云々を気にする以前に、データ量の見積もりと、適切なデータストアの選定をしっかりしてほしい。。。*1
*1:あと、物理削除バッチの作りが悪くて、爆発することも多い