PHP mysqli ドライバの max_persistent 設定の使い所がよくわからなかった件
TL;DR
- PHP の
mysqli.max_persistentで指定できるのは、HTTPワーカ プロセスあたり のコネクション数だった- 「全部で何個まで」っていう制限値じゃなかった
PHP mysqli.max_persistent 設定
Persistent Connections まわりのエントリーを先日書きました。
@do_aki さんに、PHPの mysqli ドライバには以下のようなコネクション数をコントロールする設定があると教えてもらいました。
mysqli.max_persistent integer Maximum of persistent connections that can be made. Set to 0 for unlimited.
https://www.php.net/manual/en/mysqli.configuration.php#ini.mysqli.max-persistent
これを使えば、PHPからDBサーバへ貼るコネクション数をコントロールできるのかしら?
試します
mysqli.max_persistent=1 に設定して、簡単なプログラムを実行します。
ちなみに、mysqli ドライバで持続的接続(Persistent Connections) を使うには、ホスト名 に p: とプレフィックスを付ける必要があります。
$ cat /etc/php.d/30-mysqli.ini mysqli.max_persistent=1
<?php
if (($mysqli = mysqli_connect("p:db01", "appuser", "password", ""))) {
$res = mysqli_query($mysqli, "SELECT CONNECTION_ID() as msg");
$row = mysqli_fetch_assoc($res);
echo $row['msg']."\n";
}
?>
実行したあとに、DBサーバ側でコネクション数を数えます。
mysql> SHOW PROCESSLIST; +--------+-------------+---------------------+------+---------+-<snip> | Id | User | Host | db | Command | <snip> +--------+-------------+---------------------+------+---------+-<snip> | 554589 | appuser | 192.168.X.X:36642 | NULL | Sleep | <snip> | 554590 | appuser | 192.168.X.X:36664 | NULL | Sleep | <snip> | 554591 | appuser | 192.168.X.X:36668 | NULL | Sleep | <snip> | 554592 | appuser | 192.168.X.X:36670 | NULL | Sleep | <snip> | 554593 | appuser | 192.168.X.X:36704 | NULL | Sleep | <snip>
・・・接続数が絞れてない? httpd のプロセス数と同じ数のコネクションが出来てしまっています。
プロセス毎の制限値らしい
mysqli ドライバではなく、mysql ドライバ (i のつかない方) のマニュアルには、「プロセス毎の最大値」と記載があります。 mysqli も同じ挙動だろうという推測ができますね・・・
mysql.max_persistent integer The maximum number of persistent MySQL connections per process.
<?php
$a = mysqli_connect("p:db01", "appuser", "password", "");
$b = mysqli_connect("p:db02", "appuser", "password", "");
?>
2つ接続を貼ってみると、2個目の mysqli_connect がエラーになりました。
やはり、プロセス毎でした。そして、最大数に達さないように、あふれたコネクションを閉じてくれるのではなく、エラーになるんですね。。。
$ sudo tail /var/log/httpd/error_log [Sun Aug 09 16:08:30.949737 2020] [php7:warn] [pid 19100] [client X.X.X.X:55350] PHP Warning: mysqli_connect(): Too many open persistent links (1) in /var/www/html/index.php on line 10
意図せず大量にコネクションを貼ってしまうのを防ぐためのパラメータなんですかねー・・・いまいち使い所がわからん。
MySQL Connection Pooling と Persistent Connections はチョット違うという話
コネクションプーリングのメリット
コネクションプーリングは、一度確率したコネクションを使い回す仕組みです。TCP 3-way ハンドシェイクやDBの新規接続処理をスキップすることで、パフォーマンスを向上させる効果があります。
ただ、私の経験ではコネクションプーリングは「しても、しなくてもどっちでも良い」ケースがほとんどでした。接続処理以外の部分が占める時間やリソースの方が圧倒的に多いケースがほとんどではないでしょうか。
一部、アプリケーションサーバとDBサーバの距離が非常に長く、RTT(往復時間)が大きい場合に効果があった経験はあります*1。
Connection Pooling と Persistent Connections
コネクションプーリングと似た仕組みとして、持続的データベース接続 (Persistent Connections) があります。 コネクションプーリングと持続的データベース接続は厳密に言うと少し違うものなのですが、どちらも接続を使い回す仕組みなので、私は両方「プーリング」と呼んでしまうことが多いです。その方が、通じやすいので。。。
コネクションプーリング (Connection Pooling)
アプリケーションはコネクションプールからコネクションを取出し、使い終わったら、プールにコネクションを戻します。 DBへアクセスするタイミングでのみコネクションを利用するため、アプリケーションのスレッド数(HTTPのWokerスレッド)より少ないコネクション数で済みます。HTTP の Worker スレッド 数とプールされるコネクション数は別々に管理されます。プールする接続数はドライバの設定で管理します。

プールから払い出せるコネクションがなくなると、コネクションが返却されるのを待つか、エラーになります。
「コネクションプーリング」というとこのタイプの仕組みをイメージされる方が多いのではないでしょうか。Nodejs の mysql2 はこのタイプです。
持続的データベース接続 (Persistent Connections)
Apache (Prefork) + PHP はこのタイプです。WebサーバのWokerスレッド(プロセス)とDBのコネクションが1:1で対応します。 プールが存在しないため、WebサーバのWokerスレッド数と同じ数のコネクションが張られます。

基本的にWebサーバのWokerスレッドが存在し続ける限り、コネクションが残り続けます*2。WebサーバのWokerスレッド数を増やすと連動して、DBへのコネクション数も増えます。そのため、コネクションプーリングとは異なり、HTTPサーバのWokerスレッド数を増やす場合は、接続上限に達しないよう MySQLの max_connectionsの値も増やしておく必要があります。コネクションプーリングと比較して、コネクション数のコントロールが難しい仕組みです。
Amazon Aurora レプリカ では metadata lock 待ちが発生しない
Amazon Aurora のレプリカは Vanilla MySQL のレプリケーションとは違った仕組みで実現されている。 マスターとレプリカは同じディスクボリュームを参照しており、マスターでの更新はほぼ即時レプリカに反映される。
DB クラスターボリュームは DB クラスターのデータの複数のコピーで構成されます。ただし、クラスターボリュームのデータは、DB クラスターのプライマリインスタンスおよび Aurora レプリカの 1 つの論理ボリュームとして表されます。この結果、すべての Aurora レプリカは、最短のレプリカラグでクエリの結果として同じデータを返します。 レプリカラグは、通常はプライマリインスタンスが更新を書き込んだ後、100 ミリ秒未満です。https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Replication.html
テーブル定義の変更もすぐにレプリカに反映されるのか?
仕組みから考えると、DDL (CREATE/DROP/ALTER/TRUNCATE) もレプリカに即時反映されそうだが、どうだろうか。
以下のように、マスターとレプリカでカラム数を定期的に数えるシェルを回しながら、ADD COLUMN を実行して確認してみた*1。
while [ 1 ] do sleep 1 date echo "COLUMN at MASTER $(mysql -uadmin -h <マスター> -e 'desc sbtest.sbtest1' | wc -l)" echo "COLUMN at REPLICA $(mysql -uadmin -h <レプリカ> -e 'desc sbtest.sbtest1' | wc -l)" done
- RDS MySQL
比較をわかりやすくするため、Vanilla MySQL (RDS MySQLを利用) の挙動から。MySQL では、ALTER文がレプリカで再実行されるため、マスターでかかった時間と同じぐらい時間がかかる。 そのため、時間のかかるALTER文だと大きなレプリケーション遅延が発生する。この検証ではマスターから23秒遅れでレプリカに反映されている。
Mon Jul 20 06:39:59 UTC 2020 COLUMN at MASTER 5 COLUMN at REPLICA 5 <snip> Mon Jul 20 06:40:21 UTC 2020 COLUMN at MASTER 5 COLUMN at REPLICA 5 Mon Jul 20 06:40:22 UTC 2020 COLUMN at MASTER 6 COLUMN at REPLICA 5 <snip> Mon Jul 20 06:40:44 UTC 2020 COLUMN at MASTER 6 COLUMN at REPLICA 5 Mon Jul 20 06:40:45 UTC 2020 COLUMN at MASTER 6 COLUMN at REPLICA 6
- Aurora
一方、Aurora はほぼ同時にレプリカへのカラム追加が完了している。
$ sh check.sh Mon Jul 20 05:50:26 UTC 2020 COLUMN at MASTER 7 COLUMN at REPLICA 7 <snip> Mon Jul 20 05:51:14 UTC 2020 COLUMN at MASTER 7 COLUMN at REPLICA 7 Mon Jul 20 05:51:15 UTC 2020 COLUMN at MASTER 8 COLUMN at REPLICA 8
テーブル定義の変更もAuroraではすぐレプリカに反映されることが確かめられた。
ALTERの対象テーブルへ実行中のクエリがあったら?
次は、metadata lock まわりの挙動を確認してみる。
マスター
Aurora マスターの挙動は、Vanilla MySQL と変わらない。実行中のクエリがあった場合、そのクエリが終わるまで、metadata lock 獲得待ちとなり、ALTERが待機する(Waiting for table metadata lock)。そしてさらに後続のクエリも metadata lock 待ちで待機する。
mysql> SHOW PROCESSLIST; +-----+~+---------------------------------+------------------------------------+ | Id |~| State | Info | +-----+~+---------------------------------+------------------------------------+ <snip> | 263 |~| User sleep| SELECT *, SLEEP(120) FROM sbtest.sbtest1 LIMIT 1 | | 264 |~| Waiting for table metadata lock | alter table sbtest.sbtest1 add column (cx int default 1) | | 265 |~| init | SHOW PROCESSLIST | +-----+-~-+---------------------------------+----------------------------------+ 7 rows in set (0.00 sec)
レプリカ
レプリカで SELECT *, sleep(240) FROM sbtest.sbtest1 LIMIT 1 を実行しながら、マスターに対して、ALTER TABLE sbtest.sbtest1 ADD COLUMN を実行してみる。
- RDS MySQL
Applier Thread (SQLスレッド) が、先行するクエリが終わるまで、metadata lock 獲得待ちで待機する。
マスターと同じ挙動がレプリカで再現する。
mysql> show slave status \G
*************************** 1. row ***************************
<snip>
Slave_SQL_Running_State: Waiting for table metadata lock
Master_Retry_Count: 86400
- Aurora
マスターでALTERを打ったタイミングで、レプリカで対象テーブルに対して実行中のクエリはエラーになった。 ALTERを打ったその瞬間に実行中だったクエリがエラーになるだけで、その後はALTER実行中であっても問題なくSELECTができる。
mysql> SELECT *, sleep(240) FROM sbtest.sbtest1 LIMIT 1; ERROR 2013 (HY000): Lost connection to MySQL server during query
そして、マスターでALTERが完了した直後もレプリカで実行中のクエリがエラーになった。実行中のクエリがエラーで強制終了させられるので、レプリカ側で Vanilla MySQL のように metadata lock 獲得待ちになることはなさそう。
mysql> SELECT *, sleep(240) FROM sbtest.sbtest1 LIMIT 1; ERROR 2013 (HY000): Lost connection to MySQL server during query
まとめると、ALTERの開始時と完了時にレプリカで実行中のクエリがエラーになるようだ(そのおかげで、レプリカで metadata lock 獲得待ちが発生しない)。
まとめ
- Aurora では、DDLはレプリカにすぐ反映される
- Aurora では、レプリカでの
metadata lock待ちは気にしなくてよさそう- しかし、ALTER実行によりレプリカでクエリが単発レベルのエラーになることはある
*1:v5.6 で試している
MySQLを止めずにレプリケーションをブーストする小技
先日は、MySQLユーザ会会 2020年7月に参加しました。
今回はWebや雑誌で連載の著者の方々が、執筆に至った経緯や、執筆時に心がけていることを語る回でした。 @kk2170 さんが「過去の自分に向けて書く」とおっしゃっていたのが、(そういう視点は自分の中になかったので)すごく響きました。
--
一刻も早くレプリケーション遅延を取り戻したい!そんな場合に使える小技を紹介します。
レプリケーションを止めずに有効化・無効化できるのみを取り上げています。 元に戻すのにレプリケーションを止める必要性のある方法だと、またそこでレプリケーション遅延が発生しますからね…
CPU の governor を performance に変更する
LinuxにはCPUクロックの調整機能があり、CPU governor が ondemand 設定の場合、負荷に応じて、CPUのクロック数が上下します。
クロック数を調整することで、消費電力を最適化します。
特に、(マルチスレッドスレーブを使わずに) シングルスレッドでレプリケーションを行っている場合、負荷が低いとみなされ、 クロック数が十分上がらないケースがあります。シングルスレッドのレプリケーションではCPU 1コアしか使われないためです。
performance に変更することで、常に最高クロック状態を維持することができます。
サーバの消費電力が上がってしまうのが注意点です。
# for CPU in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor > do > echo -n performance > $CPU > done
Durability を犠牲にする
InnoDB ログへの書き込み頻度を落とす
InnoDB ログ(REDOログ)への書き込み頻度を下げることで、DISK IOを少なくしパフォーマンスをブーストします。
mysql> SET GLOBAL innodb_flush_log_at_trx_commit=0; mysql> SHOW GLOBAL VARIABLES like 'innodb_flush_log_at_trx_commit'; +--------------------------------+-------+ | Variable_name | Value | +--------------------------------+-------+ | innodb_flush_log_at_trx_commit | 0 | +--------------------------------+-------+ 1 row in set (0.01 sec)
デフォルトは、innodb_flush_log_at_trx_commit=1であり、コミットする度に、InnoDB ログファイルへ書き込みが行われます。innodb_flush_log_at_trx_commit=0 では1秒おきに書き込みます。
InnoDB ログは mysqld がクラッシュしたり、サーバがダウンした際にデータが失われないようにする役割を担っています。innodb_flush_log_at_trx_commit=0 にすると障害時にデータが失われるリスクがあります。もし運悪く障害が発生してしまったら、レプリカを作り直すことになるでしょう。遅延が収まったら、有効に戻しましょう。
同様に、sync_binlog を 無効化 (0 を設定する)のも効果があります。
InnoDB ログそのものをOFFにする(MySQL 8.0.21 の新機能)
MySQL 8.0.21 からは InnoDB ログそのものを無効化することが出来るようになりました。innodb_flush_log_at_trx_commit では書き込み頻度を落とすことしか出来なかったのが、InnoDBログの存在自体を無効化できるようになりました。
ただし、innodb_flush_log_at_trx_commit=0 同様に、障害時にデータは失われてしまいます。
mysql> ALTER INSTANCE DISABLE INNODB REDO_LOG ; Query OK, 0 rows affected (0.01 sec) mysql> SHOW GLOBAL STATUS LIKE 'Innodb_redo_log_enabled'; +-------------------------+-------+ | Variable_name | Value | +-------------------------+-------+ | Innodb_redo_log_enabled | OFF | +-------------------------+-------+
パフォーマンス比較
以下のグラフは、デフォルトの状態と、{innodb_flush_log_at_trx_commit,sync_binlog} = {0,0} と、InnoDB ログを無効化したパターンのレプリケーションのパフォーマンスを簡単に計測した結果です*1。「150万件のINSERTをどれぐらいの秒数でレプリカが食いきったか」を計測しています。

InnoDB ログを無効化した場合が圧倒的に速い!!!
まとめ
- レプリ遅延で困ったら、とりあえず、InnoDB ログをOFFれ
*1:マルチスレッドスレーブを有効にし、workerを4で計測
スロークエリログをDataDogで可視化するLambda Function を作った
MySQL 徹底入門 第4版が出ましたね! 著者の方々にサインをもらいたいところですが、Stay Homeな昨今なかなかチャンスがありそうにありません。

基本、オンプレ職人なのですが、最近、ちょっとだけ、AWS Auroraを触ったりしています。
Datadog で AWS Aurora のスロークエリログを可視化する Lambda Function を作りました。 Lamda 上でクエリを正規化してから、Datadog に送信しています。
正規化して、どのクエリが多くスロークエリログに出力されているか集計しやすくしています。pt-query-digest がやってるのと同じことです。
SELECT id, name FROM tbl WHERE id = "1000"` => `SELECT id, name FROM tbl WHERE id = ? SELECT id, name FROM tbl WHERE id IN (10, 20, 30)` => `SELECT id, name FROM tbl WHERE id IN (?+)
使い方
zipファイルをlamdaに登録して、Lambdaの環境変数にDatadogのAPIキーを設定するだけで使えます。簡単。 詳しくは、README をご覧ください。
こんな感じで、スロークエリに頻出しているランキングのグラフが作れます。


グラフを作るには、Datadog のGrok parser に以下を指定して、スロークエリログから Query_time や Rows_examined 等の値をメトリックとして切り出す必要があります。いろいろなケースのログをもれなくパースできるよう、Grok parser を書くのにすごく時間がかかりました・・・
SlowLogRule ^(\# Time: (%{date("yyMMdd H:mm:ss"):date}|%{date("yyMMdd HH:mm:ss"):date})\n+)?\# User@Host: %{notSpace: user1}\[%{notSpace: user2}\] @ (%{notSpace: host}| ) *\[%{regex("[0-9.]*"): ip}\] Id:[\x20\t]+%{number: id}\n+\# Query_time: %{number: query_time} *Lock_time: %{number: lock_time} *Rows_sent: %{number: rows_sent} *Rows_examined: %{number: rows_examined}\n(SET timestamp=%{number: timestamp};\n+)?%{regex("[a-zA-Z].*"):query}.
Performance Insights じゃダメなのか
Performance Insights は、待機イベントの多いクエリを見ることはできます。 「何も待機イベントが発生していないけど、遅いクエリ」はPerformance Insights のトップSQLには掲載されてない。 実際、スロークエリログにたくさん出力されているにも関わらず、Performance Insights のトップSQLに掲載されないものがありました。
MySQL max_connections は雑に設定しておけば良い
MySQL 誕生25周年 らしいです。めでたい! 25年、1つのソフトウェアが継続しているってすごい!
max_connections について
データベースを使っている開発者から「最大までどれぐらいコネクション数を増やせるのか」という質問を良くもらいます。 最大コネクション数(max_connections) の設定値を超えてしまい、too many connections エラーが出る。 max_connections を見直すとして、「じゃあどこまで大きくしていいのか?」と不安になるのはわかる。
以下の話は、コネクションプールを使っている前提のお話。
単にコネクション数が増えるだけでは、負荷は増加しない
単にコネクション数が増えるだけでは、DBサーバの負荷はあまり変化しない。 特にMySQLはスレッドモデルで実装されており、(プロセスモデルのデータベースと比較して)大量にコネクションを張った時のリソース消費が少ない。 SQLを実行していないアイドル(Sleep)状態のコネクションは、大量に存在していても、あまりDBサーバのCPUやIOリソースの使用量には関係しない。
# Command が Sleep になっているコネクションは何も実行していない mysql> show processlist; +----+-----------------+-----------+------+---------+------+------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-----------------+-----------+------+---------+------+------------------------+------------------+ | 4 | event_scheduler | localhost | NULL | Daemon | 521 | Waiting on empty queue | NULL | | 13 | root | localhost | NULL | Sleep | 8 | | NULL | | 14 | root | localhost | NULL | Query | 0 | starting | show processlist | +----+-----------------+-----------+------+---------+------+------------------------+------------------+ 3 rows in set (0.00 sec)
apache + PHP のような、HTTPサーバのワーカスレッド(プロセス)数とDBへのコネクション数が連動してしまうような環境で、アイドルコネクションが多く発生しやすい。
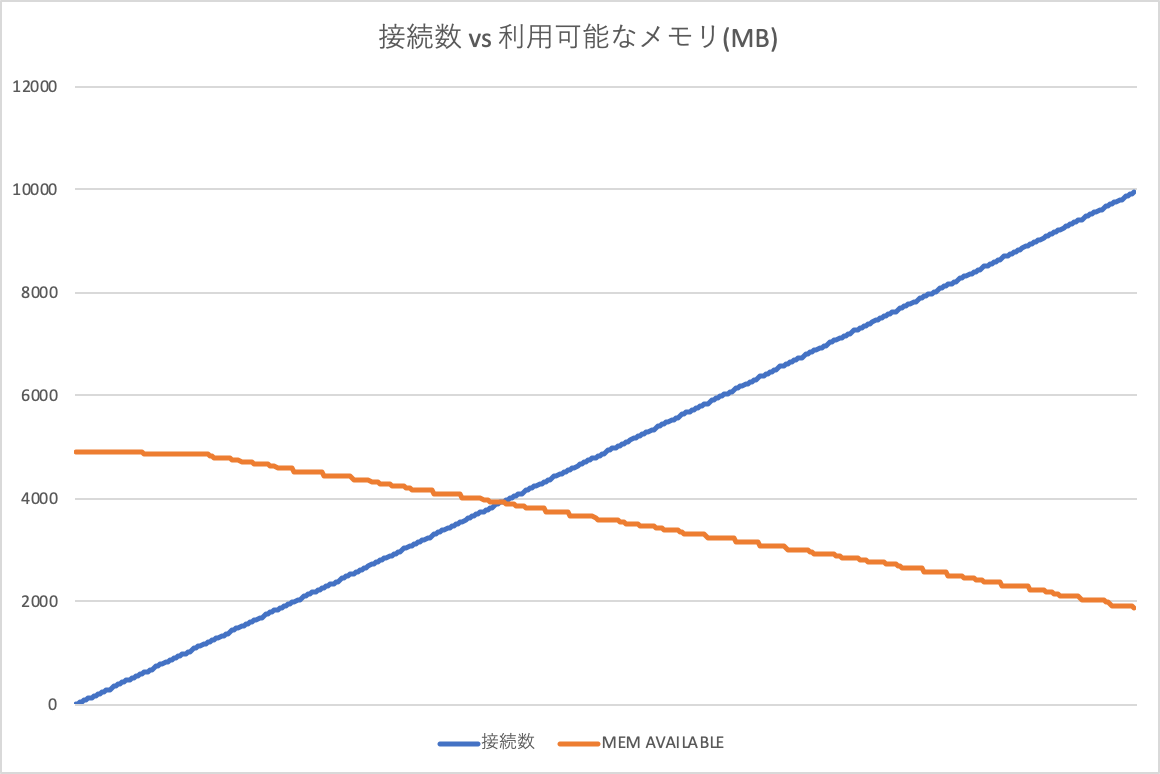
このグラフはコネクション数を約1万コネクションまで増やした時の、CPU使用率を表している。
コネクション数は SHOW PROCESSLIST で出力された数をカウントしている。
このように、いくらアイドルのコネクションを増やしたとしても、CPU使用率にほとんど影響しない。

なお、メモリは多少、必要となる。実験では1万コネクションで2Gぐらい(1コネクションあたり200KByteぐらい) 消費された*1。SQLを流していないので実際のワークロードではもう少し消費されるかもしれない)。
以下のパラメータで指定した値が、コネクションの利用するメモリ量と大きく関係している。 以下のパラメータの値が大きいほど1つのコネクション(スレッド)が必要とするメモリが大きくなる。
- sort_buffer_size
- myisam_sort_buffer_size
- read_buffer_size
- join_buffer_size
- read_rnd_buffer_size
大事なのはワークロード
DBサーバの負荷を左右するのは、コネクション数ではなく、アクティブなコネクションの数 と それぞれのコネクション(スレッド)で実行されるSQL。 アクティブなコネクションは、実際にSQLが流れているコネクションを指す。「重いSQL」 が 「同時にたくさん」流れるとDBサーバの負荷大きくなる。
アクティブなコネクション数がどれぐらいあるかは、Threads_running の値で確認できる。現在のコネクション数は Threads_connected で確認できる。
mysql> SHOW GLOBAL STATUS LIKE 'Threads_%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 0 | | Threads_connected | 2 | | Threads_created | 2 | | Threads_running | 2 | +-------------------+-------+ 4 rows in set (0.00 sec)
コネクション制限で過負荷を回避するのは困難
DBサーバの能力を超えた大量のリクエストは、データベースのレスポンスタイムを大きく低下させる。 レスポンスタイムの悪化がエンドユーザの再実行やアプリケーションからのリトライを誘発し、さらに負荷が増え、最終的には、一切、レスポンスを返せないハングアップしたような状態になってしまう。
データベースへリクエストの流入量を制限できれば、一部のリクエストは犠牲(エラー)にしつつも、サービスの提供を継続することができる。 リアルの店舗等で混雑時に入場制限をするのと同じだ。
しかし、実際には 過負荷を回避するような値に max_connections をあらかじめ設定しておくのは難しい。 DBの負荷は「SQLの内容」や「アクティブなコネクションの割合」「実行計画」といったコネクション数以外の変数の影響が大きく、コネクション数だけではコントロールできない。
キャップをかける試み自体は否定しないが、変化の激しい、Webサービスでコネクション数の見積もりに工数をかけるのは無駄が大きいように思う*2
なお、いざ過負荷に陥ったときに、max_connections を絞り、過負荷を当座で回避することは出来る。
過負荷を回避するための Thread Pool
過負荷を回避するために役立つ Thread Pool という機能がある。 Thread Pool ではアクティブなスレッド数をコントロールし、過負荷を回避し、スループットを最大に保つことができる。 MySQL では Enterprise Edition(有償) に入っている。 Percona Server (無償) にも同様の機能がある。
(しかし、自分は実運用では使ったことがないので、どこまで、うまく動いてくれるか、わからない。。。)
どこまで max_connections を増やせますか?と聞かれたら
ワークロードに変化があるのかどうをヒアリングする。現状の負荷と照らし合わせて、心配があるなら、負荷検証したり、もしもの時に備えた準備をする。 max_connections はあまり考えず、雑に大きな値(1000とか2000とか)を設定している。
参考書籍


MySQL 複数データセンター利用する場合のレプリケーショントポロジー考察
マスター・スレーブ構成ではマスター障害時、保持しているバイナリログが最も進んでいるスレーブから新マスターを選出する。
MySQLでは、どのスレーブが最新のログを持っているかはコントロールできない。 準同期レプリケーションを利用していたとしても、非同期スレーブのほうが先に進んでいるということがあり得る。
複数のデータセンターを利用する場合に、プライマリ側のデータセンターにマスターを固定する運用をするとしたら、 どのような構成パターンが良さそうか考えてみる。セカンダリ側のデータセンターのスレーブが最も進んでしまっている場合にどのように対処するか。
前提条件
- プライマリデータセンター内にロスレス準同期スレーブが最低一台は存在している前提
- サーバ障害でのデータロストは許容できない
1. 中間マスターなし

1-1. DC間フェイルオーバー有り

セカンダリのデータセンターが新マスターになる可能性がある。

マスターをプライマリのデータセンターに固定したい場合は、2段回でのフェイルオーバー動作が必要になる。 一旦、セカンダリDCのマスターにフェイルオーバーした後、プライマリDC内のスレーブをマスターに昇格しなおす。
1-2. DC間フェイルオーバー無し

プライマリのデータセンター内から必ず新マスターを選出するパターン。 プライマリ側に最新のログを持ったスレーブが存在する場合は何も問題はない。 運悪く、セカンダリDC側が先に進んでいた場合は、先に進んでしまったセカンダリDC側は破棄する必要がある。そうしないと、プライマリDC側に存在しないデータがセカンダリDC側に存在してしまう。
ここで破棄されるデータは、プライマリDC側で「まだ準同期スレーブがログを受け取っていないデータ」である。そのため、クライアントにはOKが返っていない段階。 まだ、クライアントがコミットできたことを認識してないので、破棄しても問題ない。
セカンダリDC側のスレーブが破棄される可能性があるため、セカンダリDCのスレーブを参照するような構成は取れなくなる。
2. セカンダリのデータセンターに中間マスターを配置

中間マスターを配置することで、構成が対象になり、わかりやすい。。。ように思えるが、 実際は、中間マスター死んだときのことも考えないといけないので面倒である。
2-1. DC間フェイルオーバー有り

セカンダリの中間マスターが先に進んでいた場合、中間マスターが新マスターになる。 中間マスターより、セカンダリDCのスレーブが先に進むということはあり得ないため、セカンダリDCのスレーブが新マスターとして選出されないようにすることが可能。 1-1 同様、マスターをプライマリのデータセンターに固定したい場合は、2段回でのフェイルオーバー動作が必要になる。
2-2. DC間フェイルオーバー無し

1-2 と同じ。セカンダリDC側が先に進んでしまっていた場合、セカンダリDC側は破棄する必要がある。
3. プライマリのデータセンターに中間マスターを配置

3-1. DC間フェイルオーバー有り

セカンダリDCのスレーブが、プライマリDCより先に進むことはあり得ないため、必ず、プライマリDCから新マスターが選出される。 この時、中間マスターが選出されるとは限らない。 セカンダリDC側にフェイルオーバーすることがないのがメリットだが、2 同様に、中間マスターのフェイルオーバーも考える必要がある。
3-2. DC間フェイルオーバー無し
セカンダリDCのスレーブが新マスターとなることはないため、3-1 と同じ。
まとめ
マスター・スレーブで冗長化するのむずかしい・・・考えることが多い
DC間フェイルオーバーを無しとした場合、ロストスレーブが発生しうるため、DC間F/Oは有り+2段回F/O としたほうが運用上は楽な気がする
- 1-1 が良さそう