このエントリーは TiDB Advent Calendar 2025 の 17日目の記事です。 昨日は @bohnen さんの、TiDBのMVCCを理解する(1) #TiDB - Qiita でした。
先日、MySQL でパーティションの効果について考察しました。
タイミング良く? 2025-11-27 にリリースされた、TiDB v8.5.4 で グローバルインデックスの拡張が入ってました。今回は、 TiDB でパーティションの効果(パフォーマンス)を検証したいと思います。
グローバルインデックスとは
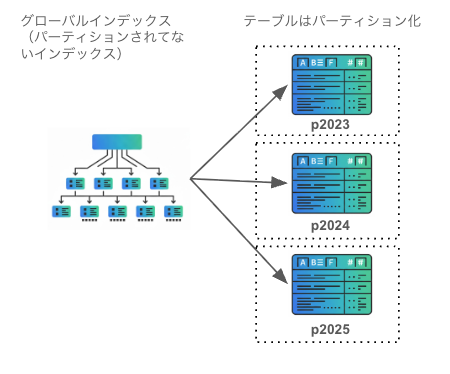
グローバルインデックスはテーブルをパーティション化した際に、そのパーティションを横断して検索できる単一のインデックスです*1。「パーティション化されてないインデックス」と捉えれば良いでしょう。
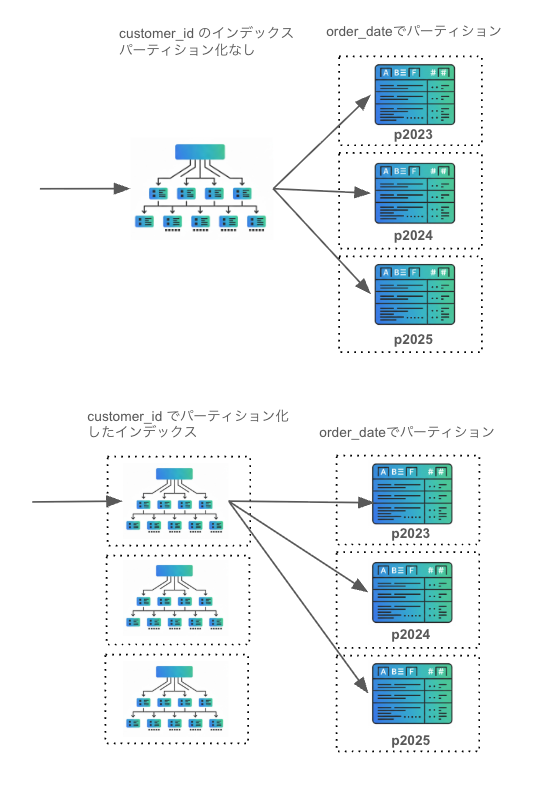
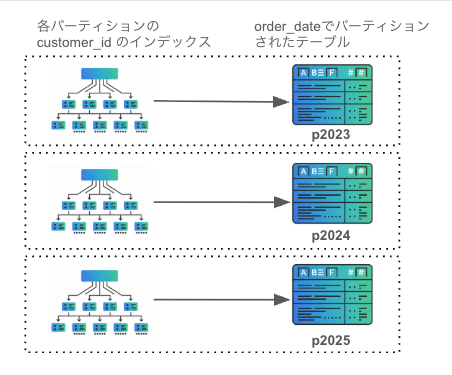
本エントリーでは、各パーティション個別に作成されるインデックスを「ローカルインデックス」と、記載します。
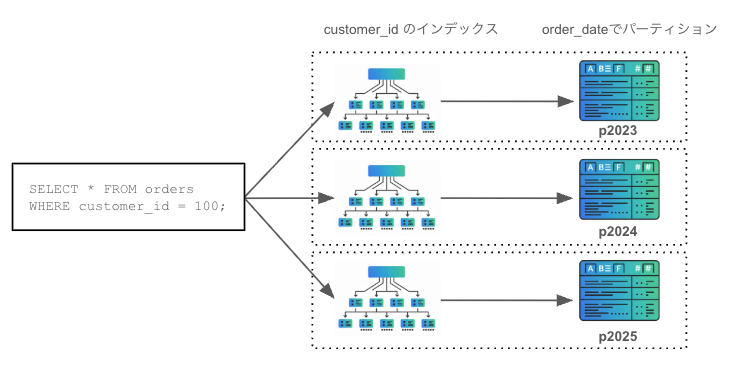
TiDB では グローバルインデックスが作成できる
Support creating global indexes on non-unique columns of partitioned tables #58650 @Defined2014 @mjonss
Starting from v8.3.0, you can create global indexes on unique columns of partitioned tables in TiDB to improve query performance. (TiDB 8.5.4 Release Notes | TiDB Docs)
MySQLではローカルインデックスしか作成できませんが、TiDB ではグローバルインデックスを選択できます。 v8.3.0 ではユニークインデックスに限られていたグローバルインデックスが v8.5.4 でその制約がなくなりました。
グローバルインデックスを作成するには、TiDB 独自の GLOBAL 句を追加します。
mysql> CREATE TABLE `t` (
-> `id` bigint NOT NULL AUTO_INCREMENT,
-> `customer_id` bigint NOT NULL,
-> `order_date` date NOT NULL,
-> PRIMARY KEY (`id`,`order_date`),
-> KEY `idx_customer_id` (`customer_id`) GLOBAL,
-> KEY `idx_order_date` (`order_date`)
-> ) ENGINE=InnoDB
-> PARTITION BY RANGE (year(`order_date`))
-> (PARTITION p2008 VALUES LESS THAN (2008),
-> PARTITION p2016 VALUES LESS THAN (2016)
-> );
Query OK, 0 rows affected (0.06 sec)
もしくは、こう。
mysql> CREATE INDEX idx_customer_id ON t(customer_id) GLOBAL; Query OK, 0 rows affected (0.27 sec)
グローバルインデックスかどうかは INFORMATION_SCHEMA.TIDB_INDEXES の IS_GLOBAL で確認できました。
mysql> SELECT TABLE_NAME, KEY_NAME, COLUMN_NAME, IS_GLOBAL FROM INFORMATION_SCHEMA.TIDB_INDEXES WHERE TABLE_NAME = 't'; +------------+-----------------+-------------+-----------+ | TABLE_NAME | KEY_NAME | COLUMN_NAME | IS_GLOBAL | +------------+-----------------+-------------+-----------+ | t | PRIMARY | id | 0 | | t | PRIMARY | order_date | 0 | | t | idx_order_date | order_date | 0 | | t | idx_customer_id | customer_id | 1 | +------------+-----------------+-------------+-----------+ 4 rows in set (0.01 sec)
なお、パーティションしていないテーブルで GLOBAL 指定するとエラーになりました。
mysql> CREATE TABLE tx (
-> id BIGINT NOT NULL AUTO_INCREMENT,
-> customer_id BIGINT NOT NULL,
-> order_date DATE NOT NULL,
-> PRIMARY KEY (id),
-> KEY idx_customer_id (customer_id) GLOBAL,
-> KEY idx_order_date (order_date))
-> ;
ERROR 8200 (HY000): Unsupported Global Index on non-partitioned table
パフォーマンステスト用のデータ
パーティションキーは order_date の年です。 パーティション化なし と パーティション数 2, 4, 8, 16 の合計 5パターンのテーブルで計測しました。
-- 16パーティションの定義
mysql> SHOW CREATE TABLE tg16 \G
*************************** 1. row ***************************
Table: tg16
Create Table: CREATE TABLE `tg16` (
`id` bigint NOT NULL AUTO_INCREMENT,
`customer_id` bigint NOT NULL,
`order_date` date NOT NULL,
PRIMARY KEY (`id`,`order_date`) /*T![clustered_index] CLUSTERED */,
KEY `idx_customer_id` (`customer_id`) /*T![global_index] GLOBAL */,
KEY `idx_order_date` (`order_date`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin AUTO_INCREMENT=10032572
PARTITION BY RANGE (YEAR(`order_date`))
(PARTITION `p2001` VALUES LESS THAN (2001),
PARTITION `p2002` VALUES LESS THAN (2002),
PARTITION `p2003` VALUES LESS THAN (2003),
PARTITION `p2004` VALUES LESS THAN (2004),
PARTITION `p2005` VALUES LESS THAN (2005),
PARTITION `p2006` VALUES LESS THAN (2006),
PARTITION `p2007` VALUES LESS THAN (2007),
PARTITION `p2008` VALUES LESS THAN (2008),
PARTITION `p2009` VALUES LESS THAN (2009),
PARTITION `p2010` VALUES LESS THAN (2010),
PARTITION `p2011` VALUES LESS THAN (2011),
PARTITION `p2012` VALUES LESS THAN (2012),
PARTITION `p2013` VALUES LESS THAN (2013),
PARTITION `p2014` VALUES LESS THAN (2014),
PARTITION `p2015` VALUES LESS THAN (2015),
PARTITION `p2016` VALUES LESS THAN (2016))
1 row in set (0.01 sec)
mysql> select count(*), year(order_date) from tp0 group by year(order_date) ORDER BY year(order_date); +----------+------------------+ | count(*) | year(order_date) | +----------+------------------+ | 625000 | 2000 | | 625000 | 2001 | | 625000 | 2002 | | 625000 | 2003 | | 625000 | 2004 | | 625000 | 2005 | | 625000 | 2006 | | 625000 | 2007 | | 625000 | 2008 | | 625000 | 2009 | | 625000 | 2010 | | 625000 | 2011 | | 625000 | 2012 | | 625000 | 2013 | | 625000 | 2014 | | 625000 | 2015 | +----------+------------------+ 16 rows in set (0.00 sec)
- レコード数は 1年あたり、625000 行、合計 1000万行。
- 各パーティションに含まれるレコード数のばらつきによる影響が出ないよう、各パーティションのレコード数は均等になるようにパーティションの区切りを調整。
- パーティション数 が 2 であれば、1パーティションあたりは 500万行、パーティション数 が 16 であれば、1パーティションあたり 62.5万行。
「パーティションプルーニングを効かせるには、ANALYZE せよ」とマニュアルにあったので、事前に ANALYZEしてからベンチマークを実行しています。
ローカル環境(PC1台)に tiup playground コマンドで TiDB x 1, TiKV x 3 をデプロイして検証しました。
最初は TiDB Cloud を使っていたのですが、安定した結果を得ることが出来ず、ローカル環境に落ち着きました。本当は分散DBなので複数台のマシンを使って確認するほうが良いんでしょうけど。
パーティションキーを含まない検索:グローバルインデックスにより性能が改善
パーティションキー order_date を含まないクエリの性能を見てみましょう。 クエリは customer_id = 1000 のレコードを1行 SELECTするシンプルなものです。
mysql> SELECT * FROM tg16 WHERE customer_id = 1000; +------+-------------+------------+ | id | customer_id | order_date | +------+-------------+------------+ | 1000 | 1000 | 2000-09-06 | +------+-------------+------------+ 1 row in set (0.00 sec)
このクエリではインデックスのみが使われます(カバーリングインデックスになってる)
mysql> EXPLAIN SELECT * FROM tp16 WHERE customer_id = 1000 \G
*************************** 1. row ***************************
id: IndexReader_6
estRows: 1.00
task: root
access object: partition:all
operator info: index:IndexRangeScan_5
*************************** 2. row ***************************
id: └─IndexRangeScan_5
estRows: 1.00
task: cop[tikv]
access object: table:tp16, index:idx_customer_id(customer_id)
operator info: range:[1000,1000], keep order:false
2 rows in set (0.00 sec)
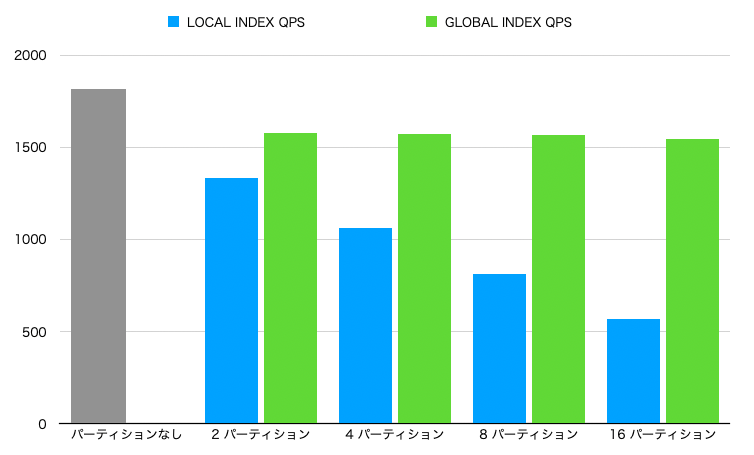
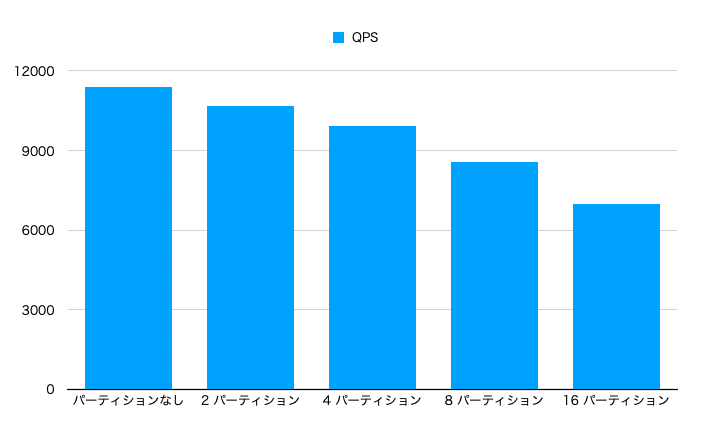
- ローカルインデックス(青グラフ)では、パーティション数を増やせば増やすほど、性能が低下しました。
パーティションキーを含まない検索xローカルインデックスでは、複数のインデックスをスキャンする必要があるため、パーティションすればするほど遅くなったと考えられます。これは想定通りの結果です。
- グローバルインデックス(緑グラフ)では、パーティションを増やしても性能劣化しなくなっています。
- グローバルインデックスはインデックスが分割されないため、パーティション数によらず、一定の性能を維持できたと考えられます。これも想定通りの結果です。
パーティションなし>グローバルインデックスになっているのは、よくわかりません。この2つのインデックスに違いはないと思ってたのですが。。。パーティション化自体に何かオーバーヘッドがあるんでしょうか。
パーティションキーを含む検索
mysql> SELECT COUNT(*) FROM tg16 WHERE order_date = "2011-01-01"; +----------+ | COUNT(*) | +----------+ | 2500 | +----------+ 1 row in set (0.00 sec)
このクエリはパーティションプルーニングが効き、1つのパーティションにしかアクセスしません。
mysql> EXPLAIN SELECT COUNT(*) FROM tg16 WHERE order_date = "2011-01-01" \G
*************************** 1. row ***************************
id: HashAgg_14
estRows: 1.00
task: root
access object:
operator info: funcs:count(Column#6)->Column#4
*************************** 2. row ***************************
id: └─IndexReader_15
estRows: 1.00
task: root
access object: partition:p2012
operator info: index:HashAgg_6
*************************** 3. row ***************************
id: └─HashAgg_6
estRows: 1.00
task: cop[tikv]
access object:
operator info: funcs:count(1)->Column#6
*************************** 4. row ***************************
id: └─Selection_13
estRows: 2494.22
task: cop[tikv]
access object:
operator info: in(_tidb_tid, 266)
*************************** 5. row ***************************
id: └─IndexRangeScan_11
estRows: 2494.22
task: cop[tikv]
access object: table:tg16, index:idx_order_date(order_date)
operator info: range:[2011-01-01,2011-01-01], keep order:false
5 rows in set (0.00 sec)
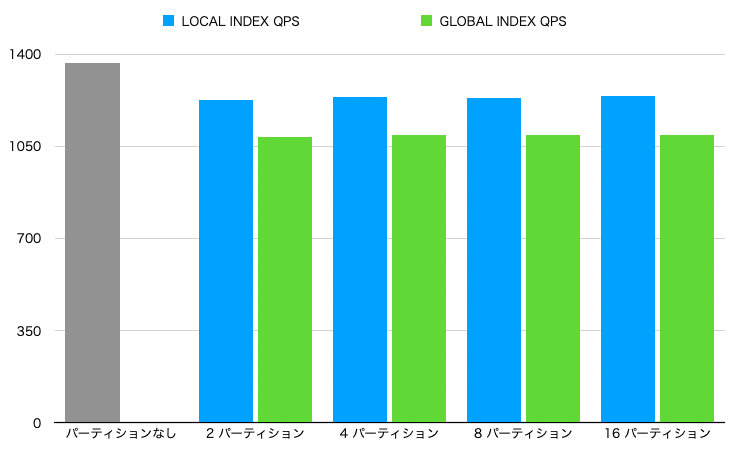
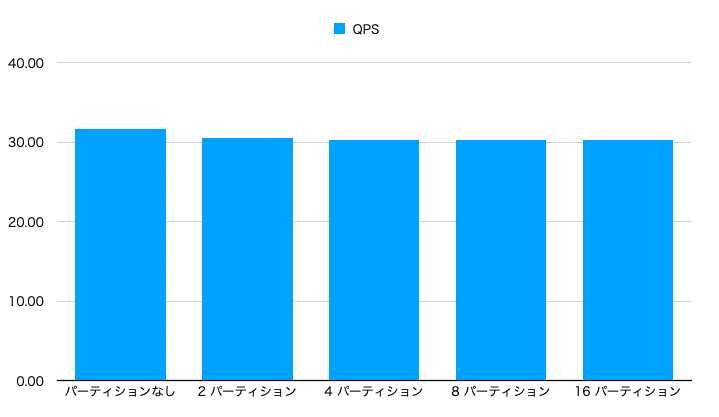
- ローカル、グローバルインデックスともに、パーティション数に限らず性能は一定でした。
- ローカルインデックス のほうが グローバルインデックス より優れたスコアでした。
- インデックスサイズが小さいローカルインデックスのほうが有利だったんでしょうか。しかし、そうすると、上記のパーティション数を増やしてもスコアが改善しなかったことと、矛盾しそうです。
- こちらも
パーティションなしが一番、良いスコアでした。- ローカルインデックスが一番良いと想定していたのですが、やはり、パーティション化自体に何かオーバーヘッドがあるのかもしれません。
フルテーブルスキャン
ヒント句を追加して、フルテーブルスキャンを選択させた場合です。
mysql> SELECT COUNT(*) FROM tg16 IGNORE INDEX (idx_order_date, idx_customer_id) WHERE order_date = "2011-01-01"; +----------+ | COUNT(*) | +----------+ | 2500 | +----------+ 1 row in set (0.56 sec)
パーティションプルーニングによって、このクエリは1つのパーティションのみをスキャンします。 パーティション数が増えるほど性能が上がる想定です。
mysql> EXPLAIN SELECT COUNT(*) FROM tg16 IGNORE INDEX (idx_order_date, idx_customer_id) WHERE order_date = "2011-01-01" \G
*************************** 1. row ***************************
id: HashAgg_13
estRows: 1.00
task: root
access object:
operator info: funcs:count(Column#5)->Column#4
*************************** 2. row ***************************
id: └─TableReader_14
estRows: 1.00
task: root
access object: partition:p2012
operator info: data:HashAgg_6
*************************** 3. row ***************************
id: └─HashAgg_6
estRows: 1.00
task: cop[tikv]
access object:
operator info: funcs:count(1)->Column#5
*************************** 4. row ***************************
id: └─Selection_12
estRows: 2494.22
task: cop[tikv]
access object:
operator info: eq(test2.tg16.order_date, 2011-01-01 00:00:00.000000)
*************************** 5. row ***************************
id: └─TableFullScan_11
estRows: 10000000.00
task: cop[tikv]
access object: table:tg16
operator info: keep order:false
5 rows in set (0.01 sec)
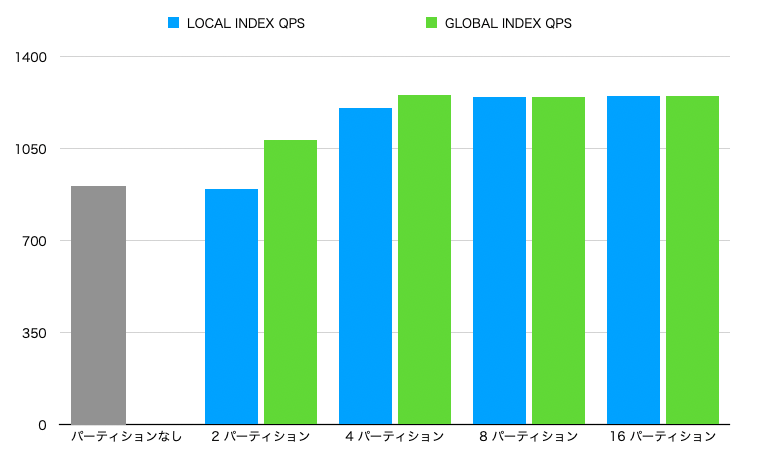
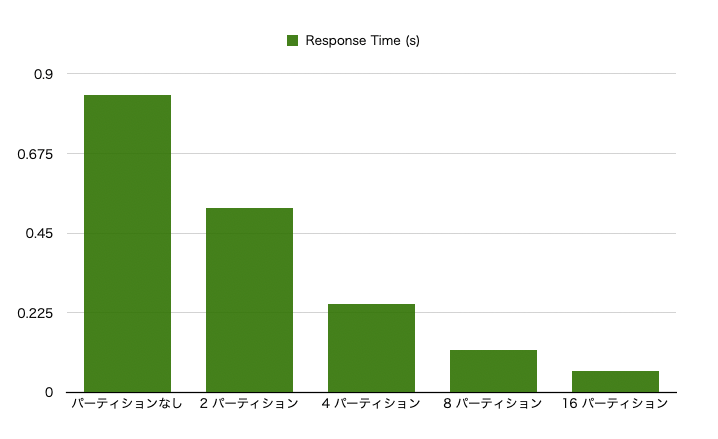
- パーティション数が増えるにしたがって、性能が上がっています。
- ローカルインデックスとグローバルインデックスでスコアに差がでました。
- インデックスは使ってないので、同じスコアが出ると予想してたのですが。。。
まとめ
- グローバルインデックスの利用により、パーティションキーを含まない検索の性能が、期待通り改善することが確認できました 。
- 一部で想定外の結果もありました。データ量が十分でなかったのかもしれません 。時間があれば深掘りしてみたいと思います。
- TiFlash とパーティションの組み合わせも確認してみたいところです。
明日は meijik さんです!